最近入ったローカル大モデルの世界ですが、実はずっと興味がありました。ただ、ノートパソコンの独立 GPU が 4G メモリの RTX 3050 Laptop しかなく、始めたくてもできませんでした。今は、Apple デバイスの推論効果も良いことが分かり、ちょうど M2 の Mac Mini を手に入れたので、非常にラッキーでした。そこでこの記事を書きました。
ユーザーフレンドリーについて言えば、通常はすぐに使えることを指し、できればグラフィカルなインターフェースがあると良いです。docker と Ollama は開箱即用と言えるかもしれませんが、グラフィカルな部分とはあまり関係がありません。私が特にお勧めしたいのは ——LM Studio です。
前期準備#
なぜこれをお勧めするのかというと、それが優れているからです。ダウンロードページを開くと、ほら、かなりモダンです。自分のシステム要件に合わせてクライアントをダウンロードすれば大丈夫です。Apple デバイスには M シリーズチップが必要です。
通常通りインストールし、開くとメイン画面が表示されます(もちろん、初めて開いたときはこんな感じではありません)。
右下のギアアイコンに目を移すと、設定を開いて言語を中国語に切り替えることができます。翻訳は完全ではありませんが、ないよりはましです。
さて、前期の準備はこれでほぼ終了です。私たちの大モデルを立ち上げる準備が整いました。
ダウンロードと大モデルの読み込み#
LM Studio が優れているのは、非常に便利な大モデルのダウンロードパスがあるからです。
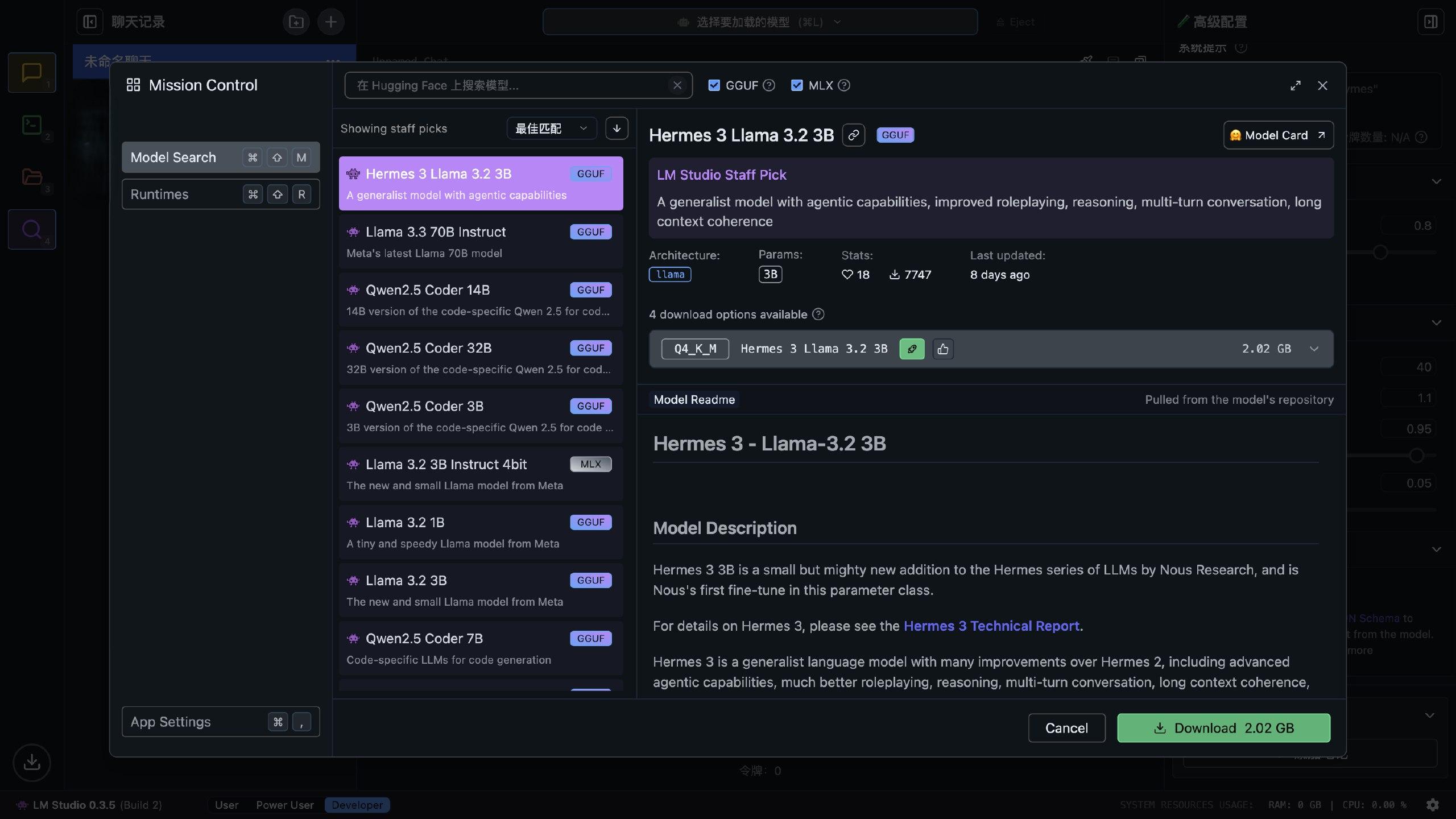
この発見の虫眼鏡をクリックするだけで(上から 4 番目)、さまざまな大モデルを検索できます。これらのモデルはすべて Hugging Face から来ているため、比較的クリーンな IP が必要です。

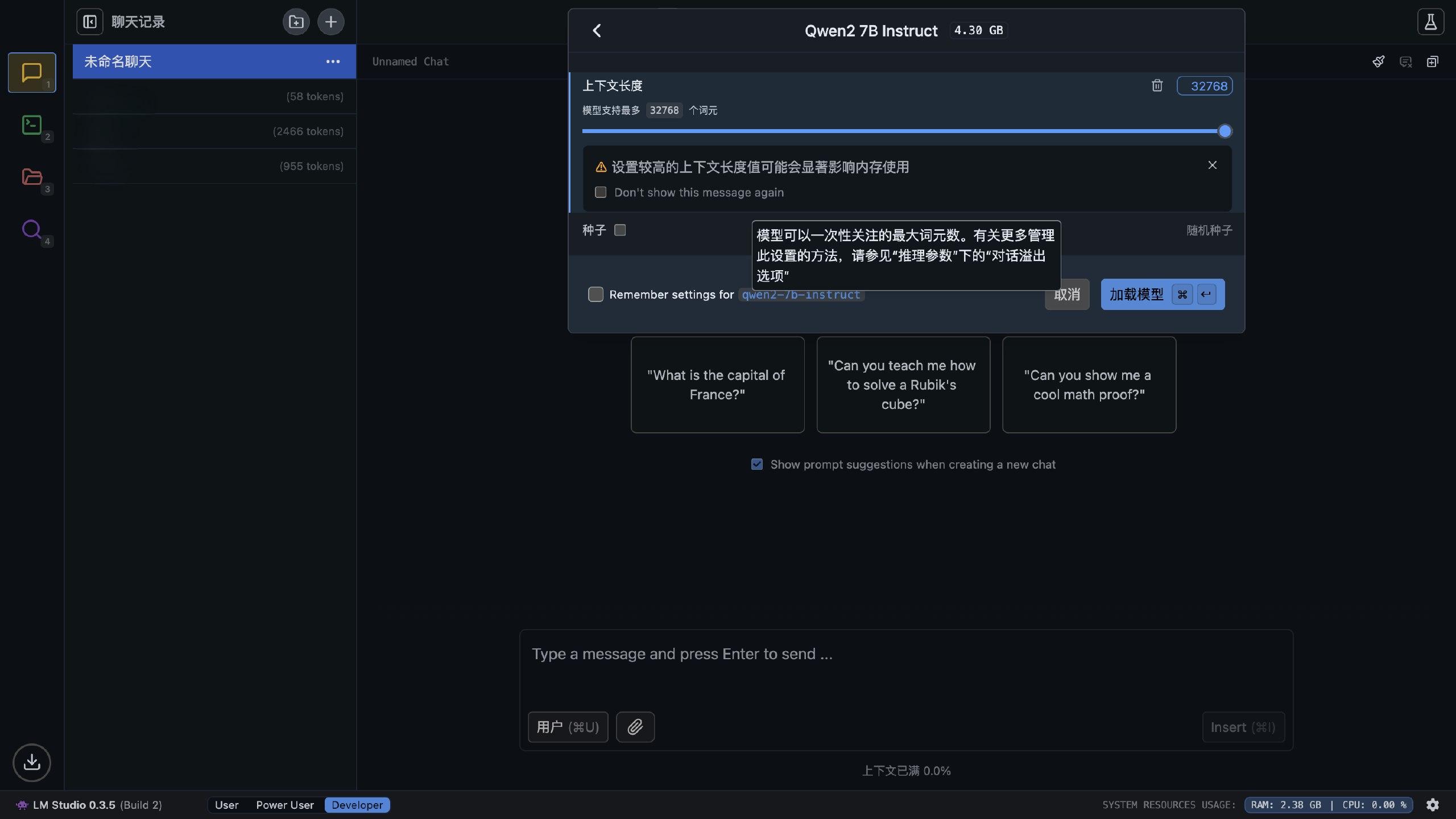
モデルのサイズを見ながら選択できます。Apple の M シリーズチップは統一メモリアーキテクチャを採用しているため、メモリと VRAM は同じメモリプールを共有します。Apple の最新情報によれば、VRAM は最大で総メモリの 75% を占有できるそうです(確かそうだったと思いますが、あまり覚えていません)。大モデルは実行中にいくつかの VRAM を消費するため、モデルのサイズは総メモリの半分程度であれば、ほぼ実行可能です。
さらに、LM Studio は Apple の MLX 深層学習フレームワークをサポートしており、データ転送のオーバーヘッドが Pytorch よりも小さく、一般的な GGUF 形式よりも M シリーズチップに適しています。そのため、モデルを選択する際は MLX のモデルを選ぶのがベストです。
モデルをダウンロードしたら、読み込むことができます。何度も実験した結果、私の 8G メモリの Mac Mini で最も良く動作するモデルは Qwen2-7B-Instruct-4bit モデルで、32k のコンテキストをフルに活用でき、速度もかなり良好で、中国語の理解能力も海外の大モデルより優れています。
正直に言うと、千問モデルが出た後、阿里云に対する印象は一変しました。阿里云のシンガポールのデータセンターが火事になったり、異地の災害復旧がほとんどなかったりしましたが、Qwen を訓練し、日本語と韓国語をネイティブにサポートするのは素晴らしいです。漫画翻訳にとっては良いニュースで、称賛に値します。馬雲先生は「一洗万古凡馬空」と言えるでしょう。
それから Qwen2-7B と対話を始めることができ、生成速度は自由に調整できますが、私の M2 を基準にすることができます。

おおよそ 19.9 tokens/s で、実用的な状態です。Phi 3 の支離滅裂な発言、Gemma 2 の中国語が分からないこと、Deepseek の大きさだけの無駄、Mistral の自問自答に比べて、Qwen2 は可愛くて穏やかです。私はそれが好きです。RAG やローカル API の呼び出しについては、次回にしましょう。
やはり 4bit の量子化はまだまだ不十分です。次回は Qwen2.5 が同じように不十分かどうか試してみます。私はやはりそれが好きで、バカだとは言いません。
この文は Mix Space によって xLog に同期更新されました。原始リンクは https://www.actorr.cn/posts/default/usingLMStudio