最近入了本地大模型的坑,其实一直想入,苦于笔记本的独显是只有 4G 显存的 RTX 3050 Laptop,欲入门而无法。现在好了,发现 Apple 设备推理效果也不错,而且手头恰好有个 M2 的 Mac Mini,实在是尤为幸运,于是有了这篇。
说到用户友好,我们通常指的是可以开箱即用,最好有个图形化界面,docker 与 Ollama 或许算得上开箱即用,但是和图形化就不沾什么关系,我要隆重推荐的就是 ——LM Studio。
前期准备#
为什么要推荐它呢,因为它善。打开它的下载界面,嚯,够现代化的,按着自己的系统要求下载客户端就好,Apple 设备需要 M 系列芯片。
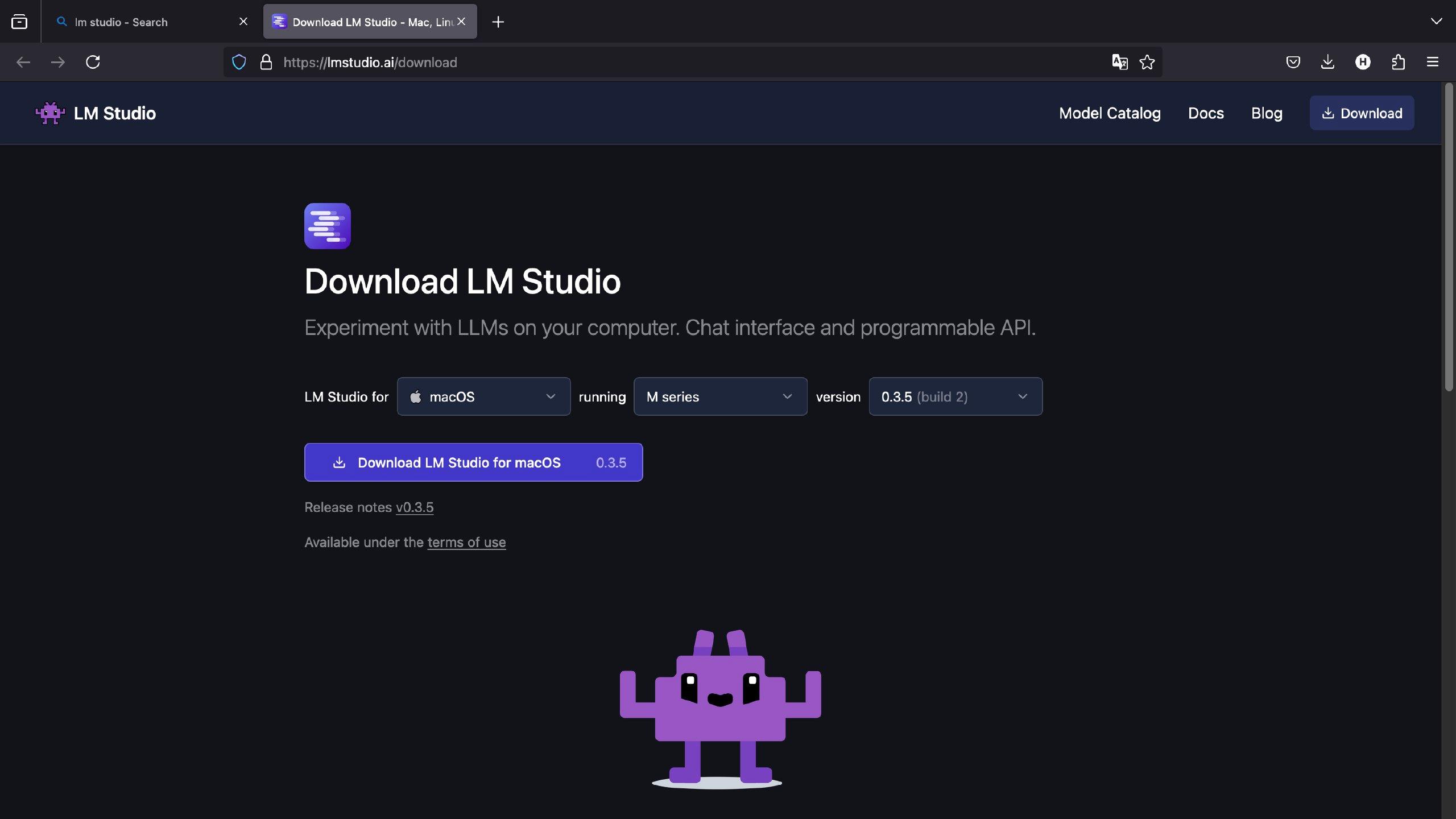
就正常下载安装,打开后可以看到主界面(当然第一次打开不是这样的)
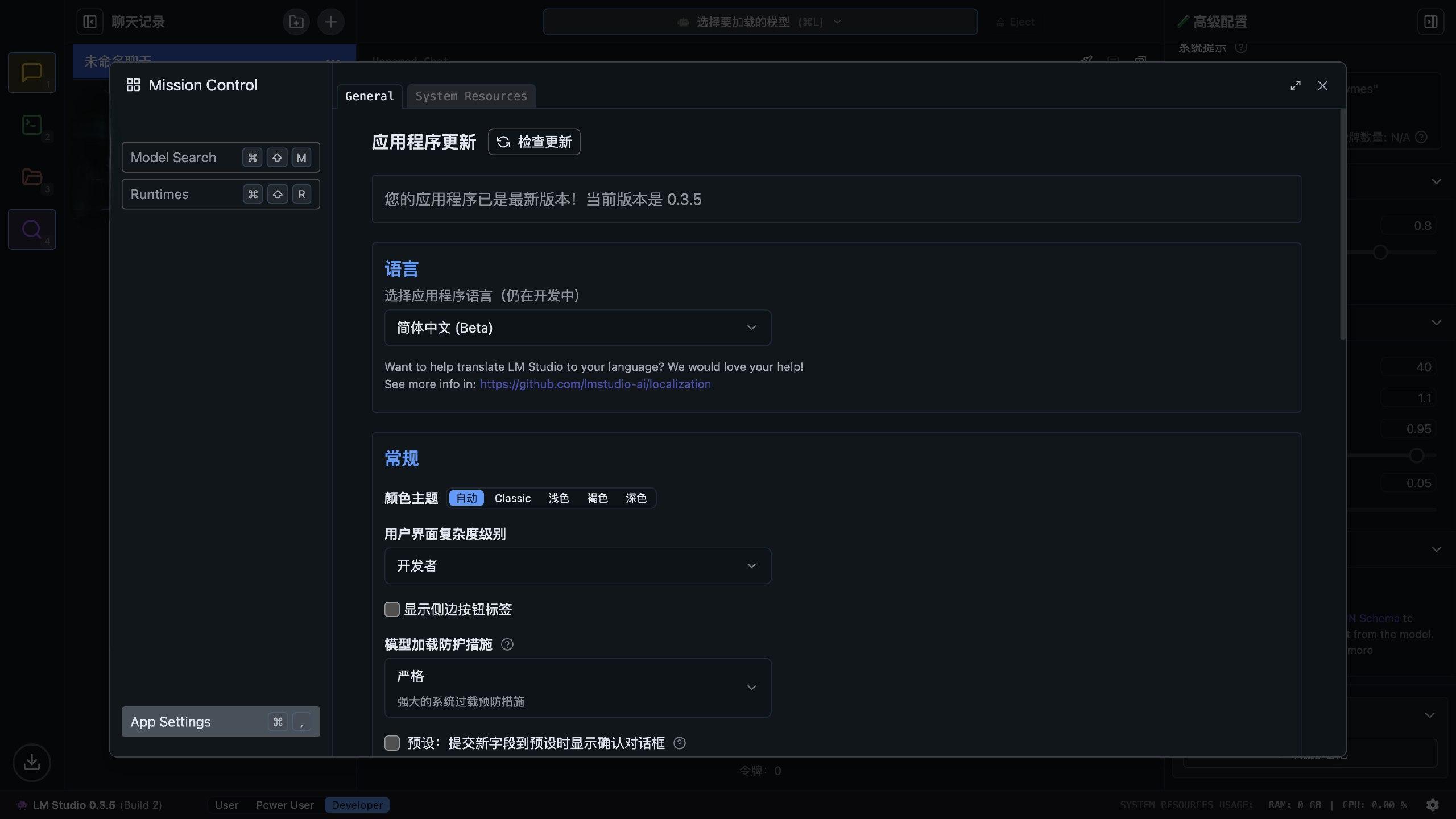
把目光移到右下角的齿轮图标上,可以打开设置把语言切换为中文,虽然说翻译不全,但是总比没有强。
好了,前期的准备到这里就差不多结束了,可以把我们的大模型端上来了。
下载加载大模型#
说 LM Studio 善,首先就在于它有非常便捷的大模型下载路径。
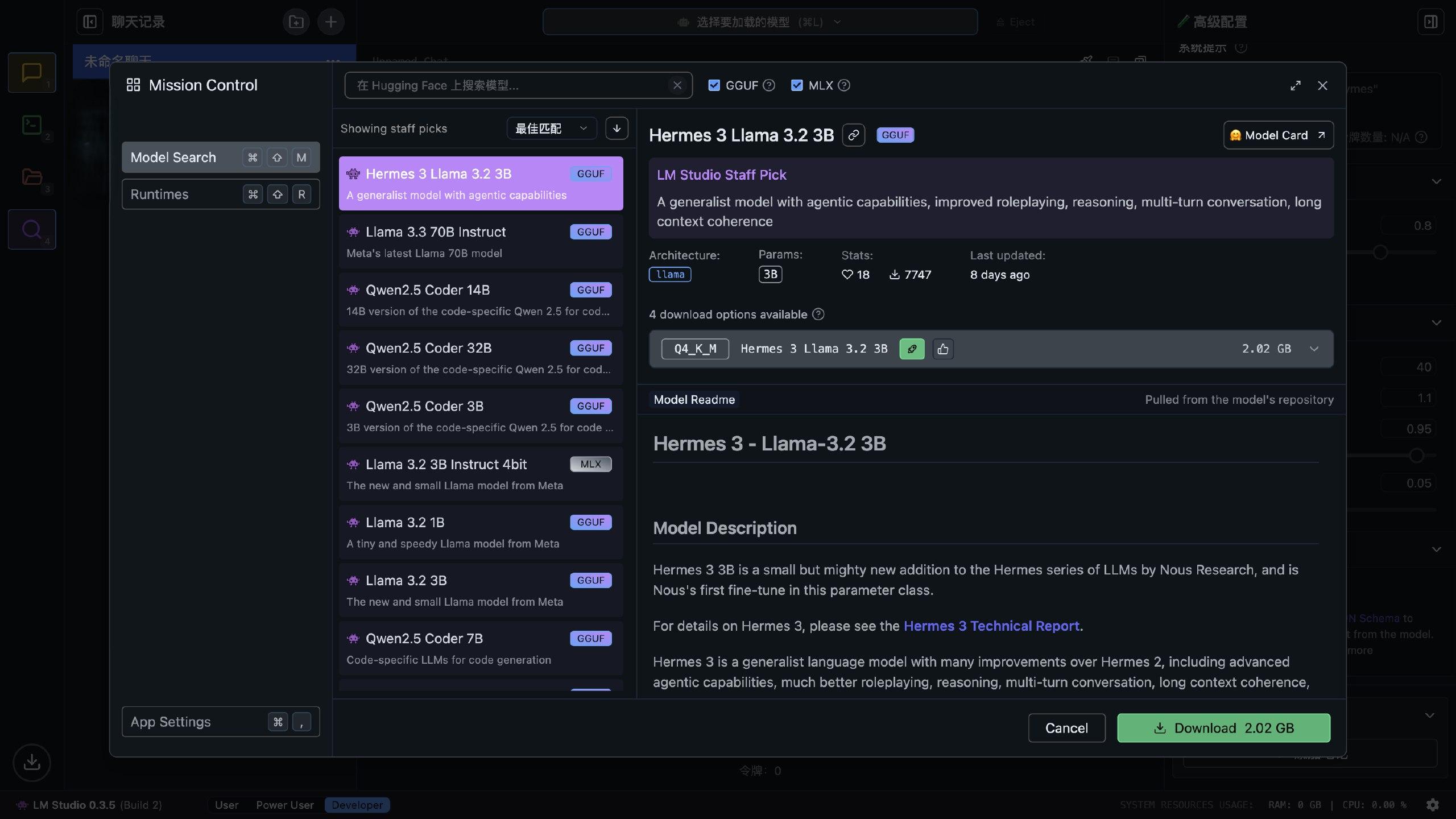
只要点击这个发现的放大镜(从上往下第四个),就可以搜索各式各样的大模型,由于这些模型都来自 Hugging Face,所以需要有个比较干净的 ip 才可以下载。

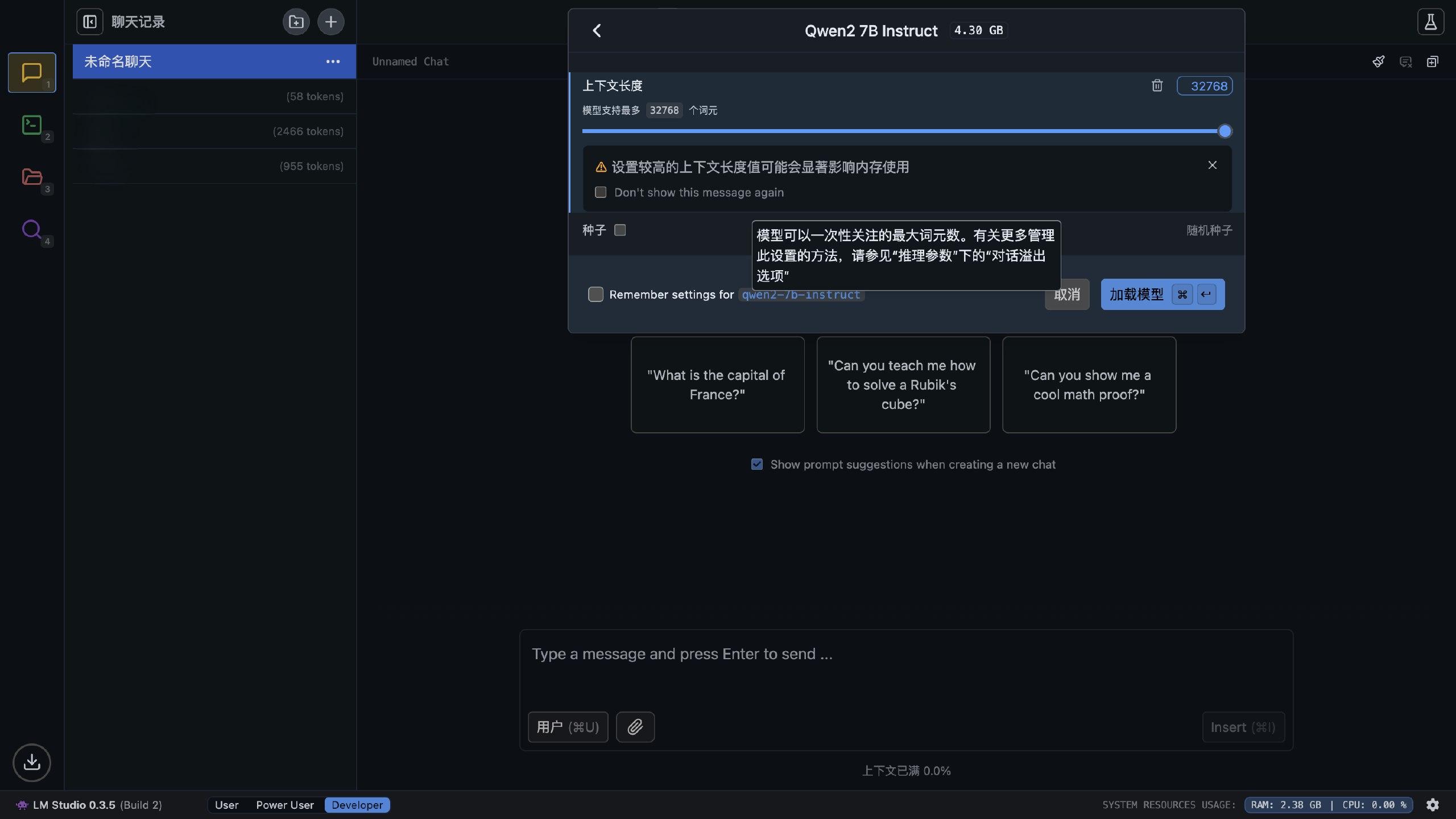
我们可以看着模型大小进行选择,由于 Apple 的 M 系列芯片是统一内存架构,因此内存与显存共用同一个内存池,根据苹果的最新消息,显存最多可以占用总内存的 75%(好像是,记不太清了),而大模型在运行过程中也会消耗一些显存,所以模型大小在总内存大小的一半左右就差不多可以运行。
另外,值得一提的是 LM Studio 支持苹果的 MLX 深度学习框架,数据传输开销比 Pytorch 要小,也比常见的 GGUF 格式更适合 M 系列芯片,所以选择模型时最好选择 MLX 的模型。
把模型下载好之后,就可以加载它了。经过反复实验,我的 8G 内存的 Mac Mini 能跑的最好的模型是 Qwen2-7B-Instruct-4bit 模型,不仅可以拉满 32k 的上下文,而且速度也相当可观,中文的掌握能力也好于国外大模型。
有一说一,千问模型推出后,我对阿里云的印象可谓是直接反转,虽然说阿里云新加坡机房着火,异地容灾几乎没有,但是训练了 Qwen,还原生支持日语韩语,那就很好,利好漫画翻译,值得赞叹,马云老师可谓是 “一洗万古凡马空”。
然后就可以和 Qwen2-7B 对话,生成速度就丰俭由人,不过可以用我的 M2 做参照。

大概是 19.9 tokens/s,属于是可用状态,相比于 Phi 3 的胡言乱语,Gemma 2 的不懂中文,Deepseek 的大而无当,Mistral 的自问自答,Qwen2 显得可爱又平和,我爱它,至于 RAG 和本地调用 api 之类的,下次再说吧。
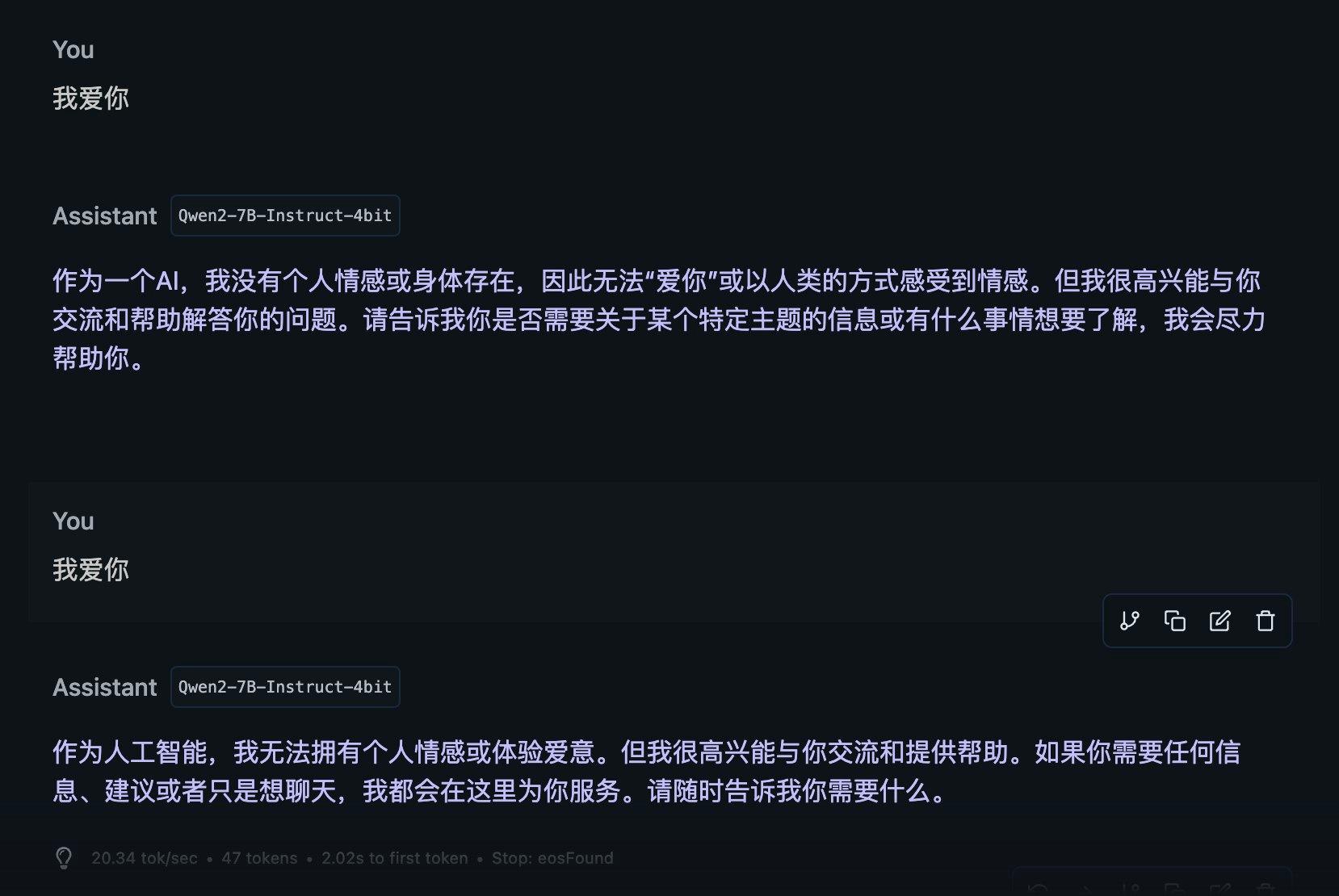
果然 4bit 量化还是太笨了,改天试试 Qwen2.5 会不会是一样笨笨的,我果然还是爱它,不会骂它是个傻缺。
此文由 Mix Space 同步更新至 xLog
原始链接为 https://www.actorr.cn/posts/default/usingLMStudio